Data Scientist là gì?
Data Scientist (kỹ sư khoa học dữ liệu) là những người phân tích, sắp xếp và thay dữ liệu “kể chuyện”, bất kể nó có cấu trúc hay không. Công việc của họ sẽ cần phối hợp giữa cả khoa học máy tính, thống kê và toán học. Họ sẽ là người phân tích, xử lý và “mô hình hóa” các dữ liệu, sau đó diễn giải các kết quả để tạo ra các kế hoạch hoạt động cho team và doanh nghiệp.
Nói một cách khác, nghề data scientist làm việc cùng dữ liệu và cho ra các insight mang tính phân tích. Họ sẽ truyền đạt các phát hiện và insight này với các bên liên quan – từ lãnh đạo cấp cao, quản lý đến khách hàng. Từ đó các công ty có thể trực tiếp hưởng lợi từ việc đưa ra các quyết định sáng suốt nhất để thúc đẩy tăng trưởng kinh doanh và lợi nhuận của họ.
Tại Việt Nam, ngành CNTT cũng đang chứng kiến sự tăng trưởng tiềm năng của ngành Khoa học dữ liệu. Ngày càng có nhiều doanh nghiệp quan tâm hơn tới ngành khoa học dữ liệu và sẵn sàng đổ tiền cho việc nghiên cứu và phát triển. Không sai khi nói nghề Data Scientist đang là một trong những ngành hot nhất trên thị trường Việt Nam.
Công việc của một Data Scientist

Credit: Matt Dancho
Mục tiêu của bộ phận Data Science là làm sao để các bộ phận các tại Doanh nghiệp có thể đưa ra các quyết định dựa trên dữ liệu tốt hơn. Vì thế Data Science có vai trò hỗ trợ (tương tự như CNTT) cho phép tổ chức hoạt động tốt hơn và tăng giá trị nhanh hơn thông qua việc ra quyết định tốt hơn.
Luồng công việc của bộ phận Data Science sẽ gồm các Cột mốc quan trọng (đám mây), các giai đoạn (đường kẻ đứt nét) và các bước (box màu xám). Quy trình bắt đầu từ một vấn đề cụ thể (Cột mốc 1) – doanh nghiệp sẽ ưu tiên đưa vấn đề này đến nhóm khoa học dữ liệu và họ sẽ bắt đầu vào quy trình quản lý dự án.
Chu trình Data Science có 3 giai đoạn:
- Chuẩn bị – Dữ liệu được thu thập và làm sạch. Điều này cần một lượng thời gian đáng kể vì hầu hết dữ liệu còn nhiễu, có nghĩa là cần thực hiện các bước để cải thiện chất lượng và chuyển nó sang thành định dạng mà máy có thể hiểu và đọc.
- Thử nghiệm – Đây là nơi các giả thuyết được tạo ra, dữ liệu được trực quan hóa và các mô hình được tạo ra. Điều này mất ít thời gian hơn so với khâu Chuẩn bị.
- Phân phối – Báo cáo kết quả được ghi lại thành tài liệu, slideshow trình bày cho quản lý và một khi quản lý thông qua, các quyết định sẽ được truyền tải xuống để thay đổi.
Khi kết thúc quy trình, phần triển khai này sẽ là lúc một Business Value (cột mốc) mới cho doanh nghiệp được tạo ra.
Phân biệt Data Scientist vs Data Engineer vs Data Analyst
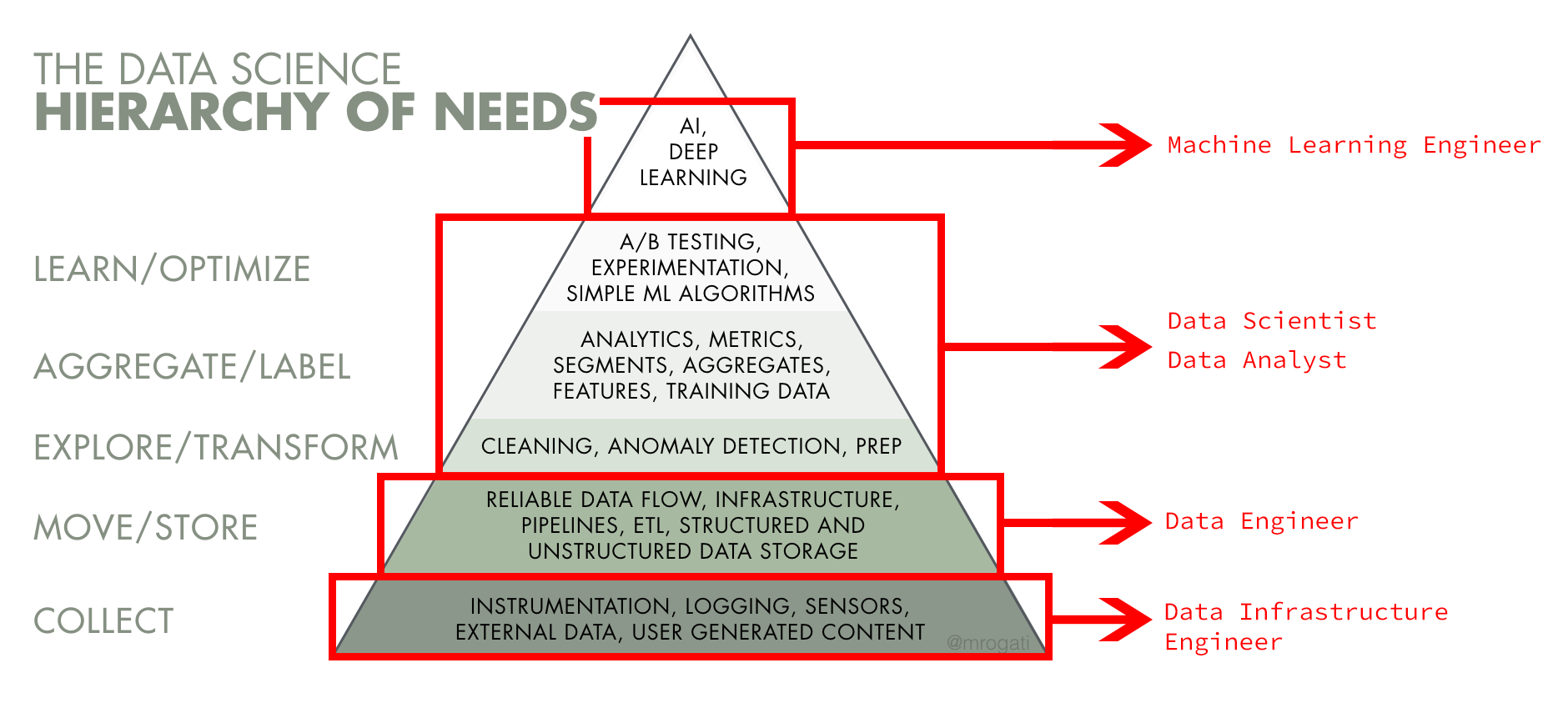
“Tháp workflow” của bộ phận Data Science
Tuỳ thuộc vào quy mô và mô hình doanh nghiệp, mỗi vị trí tại mỗi tổ chức sẽ có vai trò và trách nhiệm khác nhau. Tuy nhiên, mô hình tổng quan nhất về sự khác nhau của bộ ba Data như sau:
- Data Scientist sẽ phân tích, kiểm tra, tổng hợp, tối ưu hóa dữ liệu và trình bày nó cho công ty. Các nhà khoa học dữ liệu thường có 4 nhiệm vụ chính trong một công ty: Phân tích, kiểm tra, tạo và trình bày chúng cho nhóm. Các nhà khoa học dữ liệu phải có một nền tảng toán học và thống kê. Họ cũng hiểu và thành thạo việc tạo ra các mô hình máy học và trí tuệ nhân tạo. Việc tìm kiếm Data Scientist của doanh nghiệp cũng như tìm kiếm một Full-stacker và đòi hỏi nhiều thời gian.
- Data Engineers sẽ phụ trách thu thập dữ liệu liên quan. Họ di chuyển và biến đổi Dữ liệu này thành “Pipeline” cho bộ nhóm Khoa học dữ liệu. Họ có thể sử dụng các ngôn ngữ lập trình như Java, Scala, C ++ hoặc Python tùy theo nhiệm vụ của họ. Kỹ sư dữ liệu chuyên về 3 hành động dữ liệu chính: thiết kế, xây dựng và sắp xếp các đường ống dữ liệu. Có thể gọi họ là loại kiến trúc sư dữ liệu. Kỹ sư dữ liệu thường có kỹ thuật máy tính hoặc nền tảng khoa học và kỹ năng tạo hệ thống.
- Data Analysts cũng sẽ tham gia vào việc lấy dữ liệu liên quan từ nhiều nguồn khác nhau và chuẩn bị nó để phân tích thêm. Dựa trên phân tích, một nhà phân tích dữ liệu cần đưa ra kết luận, hoàn thành các báo cáo cùng hình ảnh minh hoạ.
Workload của một Data Scientist
Nhìn vào nhánh Data Science, hầu hết mọi người sẽ nói rằng Data Science = Machine Learning. Tuy nhiên trên thực tế, Machine Learning (hoặc Modeling) sẽ chỉ chiếm khoảng 20% trong workload của một Data Scientist. Phần trăm công việc của Data Scientist được phân chia như sau:
- Hiểu vấn đề của doanh nghiệp: Tiếp xúc và giao tiếp với Lãnh đạo/ Khách hàng (15%)
- Làm việc của Dữ liệu: Lọc sạch dữ liệu, Học data, Visual hoá, Xử lý, Chuyển đổi, và Thấu hiểu (70%)
- Truyền tải kết quả: Báo cáo, Soạn Slide Decking, và Build nên Công cụ ra quyết định tự động) (15%)
Data scientist sẽ dựa vào phân tích dự đoán, học máy, điều hòa dữ liệu, mô hình toán học và phân tích thống kê. Một chuyên gia dữ liệu sẽ tiến hành xử lý khối lượng dữ liệu lớn theo quy trình như sau:
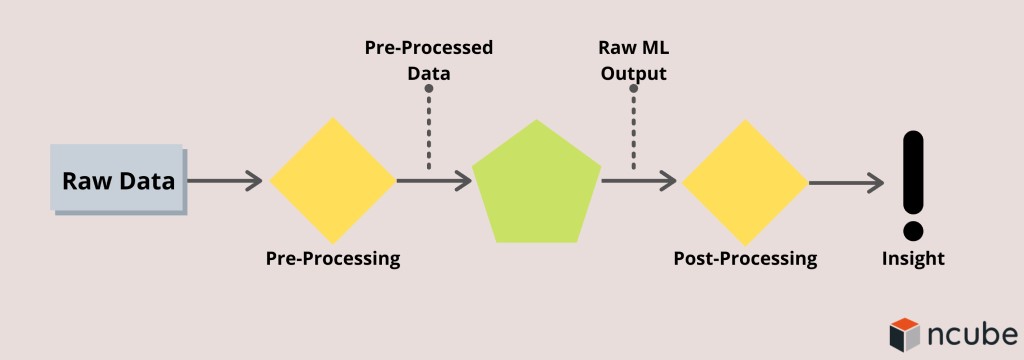
Machine Learning Model
Việc xây dựng các mô hình máy học Machine Learning models chỉ là một bước của cả quá trình workload của một nhà khoa học dữ liệu. Sau khi đầu ra mô hình xử lý hậu kỳ, Data scientist sẽ truyền đạt kết quả cho các nhà quản lý, thường sử dụng các phương tiện trực quan hóa dữ liệu. Khi kết quả được thông qua, nhà khoa học dữ liệu đảm bảo công việc được tự động hóa và được phân phối một cách thường xuyên.
Nói tóm lại, người làm Data Scientist sẽ bao gồm:
- Áp dụng các kỹ thuật định lượng từ kiến thức về thống kê, kinh tế lượng, optimizations và machine learning / deep learning về giải pháp cho doanh nghiệp từ nhiều lĩnh vực
- Vận dụng các phương pháp thống kê để xây dựng các mô hình dự đoán
- “Mở đường” cho việc ra quyết định dựa trên insight phân tích từ các bộ data có cấu trúc và không cấu trúc
- Xác định các nguồn dữ liệu mới và khám phá tiềm năng sử dụng của chúng trong việc phát triển thêm các insight trong phát triển sản phẩm
- Khám phá công nghệ mới và các giải pháp phân tích để sử dụng trong phát triển mô hình định lượng
- Thiết kế và phát triển các báo cáo và bảng điều khiển tương tác tùy chỉnh
- Duy trì và cải thiện các mô hình hiện có
- Truyền tải insight và các phân tích với dàn lãnh đạo và Stakeholder cũng như các phòng ban liên quan để tiến hành thay đổi/ cập nhật
Lộ trình trở thành Data Scientist
Các ngôn ngữ Lập trình cơ bản
Python : Python xứng đáng có một vị trí cao ổn định trong bộ toolkit của một Data Scientist. Nhiều chuyên gia chọn ngôn ngữ này vì hệ sinh thái được thiết kế đặc biệt cho khoa học dữ liệu. Python có cộng đồng phân tích dữ liệu lớn nhất, sẽ dễ dàng tìm thấy các ví dụ về phân tích trong Kaggle, tìm các ví dụ mã trong Stackoverflow (trang web hỏi đáp với hầu hết người mới bắt đầu và thường nâng cao câu hỏi là tốt) và cơ hội việc làm vì nó là ngôn ngữ phổ biến nhất trên thị trường.
SQL: Việc “nói cùng ngôn ngữ với database” là điều cần thiết cho các nhà khoa học dữ liệu, cần phải thành thạo SQL để có thể lấy thông tin từ cơ sở dữ liệu bằng cách sử dụng các hướng dẫn truy vấn mà không cần phải nối mã tùy chỉnh.
R: Với nhiều tính năng đặc biệt, R là ngôn ngữ được “làm thủ công” dành riêng cho data science và là khởi đầu cần thiết cho các Data Scientist. Mọi thông tin và vấn đề số liệu sẽ được xử lý bằng R.
Hadoop: Mặc dù kiến thức về công cụ này là không bắt buộc, nhưng Hadoop làm tăng giá trị và khả năng chuyên môn của một nhà khoa học dữ liệu, đặc biệt nếu họ có kinh nghiệm với Hive hoặc Pig. Các công cụ đám mây như Amazon S3 cũng có thể giúp ích rất nhiều.
Machine Learning
Cung cấp một kiến thức khổng lồ để hiểu cách các mô hình khác nhau hoạt động bên trong và thậm chí nghĩ về mô hình tốt hơn cho từng vấn đề.
Thống kê (Statistics)
Kỹ năng này sẽ phân biệt là Data scientist và Machine Learning Engineer. Kiến thức về thống kê: thống kê mô tả, biết cách thực hiện phân tích dữ liệu khám phá tốt (EDA) hoặc tối thiểu là các khái niệm cơ bản về xác suất và suy luận, hiểu rõ các khái niệm về sai lệch lựa chọn, Nghịch lý Simpson, liên kết các biến (cụ thể là phương pháp phân tách phương sai ), những điều cơ bản của suy luận thống kê (và thử nghiệm A / B nổi tiếng như suy luận được biết đến trên thị trường), và một ý tưởng cho thiết kế thử nghiệm.

Soft Skill: Suy nghĩ như một Data Scientist
Việc tự trau dồi và rèn luyện tư duy của một Data Scientist là một trong những kỹ năng quan trọng để phân biệt giữa một Scientist giỏi và một Scientist vừa đủ. Một số gợi ý cho bạn để tự rèn luyện cho mình:
-
Luôn tò mò: Hãy luôn đặt câu hỏi “Vi sao?”, tìm liên kết và những thông tin mới với những vấn đề trong cuộc sống hằng ngày. Trong công việc, các nhà khoa học dữ liệu cho ra insight từ dữ liệu và thông tin từ dataset và đưa ra các quyết định quan trọng theo đó. Việc phân tích hoàn hảo sẽ không hữu ích nếu nó không giải quyết được vấn đề cơ bản. Đôi khi bạn cần quay lại, thử một cách tiếp cận mới và điều chỉnh lại câu hỏi bạn đang cố gắng trả lời. Hãy luôn đặt câu hỏi.
-
Có tính tiểu tiết: Các nhà khoa học dữ liệu sử dụng rất nhiều công cụ để quản lý quy trình công việc, dữ liệu, chú thích và mã của họ. Điều quan trọng là phải làm việc khoa học, quan sát, thử nghiệm và ghi chép lại mọi lúc, để bạn có thể xem lại và suy nghĩ. Ngoài ra cần phải lưu lại tất cả các nghiên cứu, thông tin bạn phát hiện được không chỉ ở hiện tại – trong quá khứ nữa.
-
Biết sáng tạo: Nghe thì có vẻ mâu thuẫn, nhưng khoa học dữ liệu cần được tiếp cận ở nhiều cách thức – phương diện và góc nhìn khác nhau. Bạn không nhất thiết phải có background kĩ thuật, nhưng bạn cần phải có tư duy sáng tạo. Thông thường, suy nghĩ thay thế (alternative thinking) là chìa khóa cho cách bạn giải quyết một vấn đề mới. Nó sễ đi song song của tư duy logic để giúp bạn thành công trong nghiên cứu và giải mã insight.
Tìm kiếm các nguồn học tập dành cho Data Scientist
- Machine Learning (Google ML): Các khóa học nhanh được update liên tục từ Google.
- Deep Learning (Kaggle Learn): Sản phẩm mới từ Kaggle bên cạnh động đồng Kaggle đang hot, từ lý thuyết nhỏ đi kèm với nhiều ứng dụng thực tế.
- Python for Data Science and Machine Learning (Udemy): Giải thích rất rõ ràng về các khái niệm khác nhau của cả khoa học dữ liệu và máy học. Khóa học này sẽ giúp bạn thành thạo thư viện scikit-learn phổ biến cho máy học. Nó cũng bao gồm phần giới thiệu về Spark và TensorFlow.
- Complete SQL Bootcamp (Udemy): Một nhà khoa học dữ liệu cần có nhiều công cụ hơn trong kho vũ khí của mình hơn là chỉ lập trình R và Python. SQL là một ngôn ngữ quan trọng khác mà bạn sẽ thường sử dụng để tương tác với cơ sở dữ liệu. Khóa học này đã giúp tôi có được thực tập hiện tại và dạy tôi mọi thứ tôi cần biết về SQL trong hai ngày.
- DataCamp: DataCamp có các khoá học từ 4-6 tiếng. Các khóa học này có các video giải thích ngắn và sau đó bạn sẽ có các bài tập để áp dụng các nguyên tắc từ các video. Mọi thứ xảy ra trong trình duyệt của bạn, vì vậy bạn không phải cài đặt bất cứ thứ gì. Điều này làm cho DataCamp trở thành sự giới thiệu hoàn hảo cho lập trình R và Python.